Shopify tell you not to edit content_for_header for good reason. The code that Shopify outputs here could change format and any modifications based on find and replace could break in unexpected ways. But sometimes it’s fun to live on the edge, or maybe you just need to debug something.
Use this in production at your own risk. The example (preloads.js) is a basic proof of concept.
Below is the way I’ve done it in the past. Also see another approach from OutOfTheSandbox on GitHub.
Step 1: Find the content_for_header line in theme.liquid
{{ content_for_header }}
How to locate: Shopify Admin> Online Store > Themes > Edit code > themes.liquid
Wraps the {{content_for_header}} in a comment so that it exists in the themes.liquid file
This is because Shopify does a simple theme code check to test if it exists and won’t let you save the theme file if not. The comment also means nothing actually gets output.
Assigns a string to variable custom_content_for_header
The string becomes the modified output of the original CFH
The | replace filter is used to find, replace
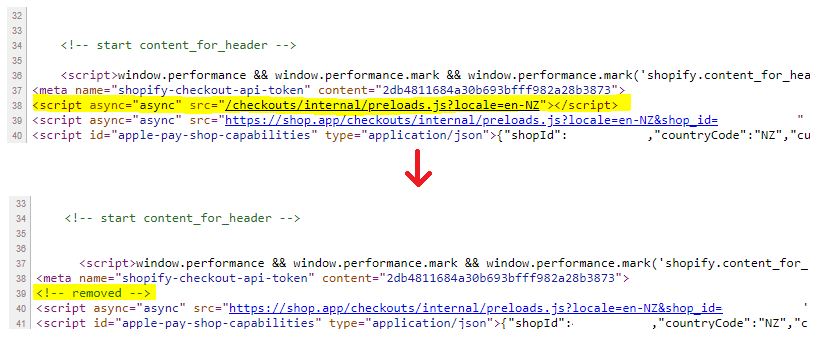
Find the JS script to remove: <script async="async" src="<script async="async" src="/checkouts/internal/preloads.js?locale=en-NZ"></script>
Replace with an HTML comment to help verify it worked <!-- removed -->
Then we print the modified string
Step 3: Check view-source
Hopefully it worked the way you wanted it to!
Just a side note – remove or minify preloads.js in Shopify?
I don’t recommend removing or fiddling with the preloads.js file as it has very little real world impact and has some UX benefits. Counter-intuitively its presence on a page can increase the page load speed of following pages.
Some SEO tools (looking at you SEMrush) will generate some scary looking warnings which lead some website owners to crudely try and fix or remove or minify preloads.js from Shopify without a clear reason, other than “must get rid of all SEMrush errors”.
Blindly following an SEO audit report to try and fix all errors is not always a productive use of time, not a very good SEO tactic.
However, it would be nice if Shopify minified the file on output so that it didn’t generate so many scary looking errors.
Seems to be canonicalised to home by default and uses the same template. Unsure what its original use was. Seems like a legacy holdover of some sort.
/collections/all – the all products page
This is a meta-collection that literally contains ALL products on your site. Even products you may not have included in other collections. If you want to control what is allowed in this page, you’ll need ‘override’ it by creating a collection with the /all handle.
Collection page ?order= URL parameter
Something unusual happens when you have an order= parameter in a collection page URLs, it adds it to the {{ canonical_url }}
From June 2021, robots.txt became editable in Shopify. But how do you edit it? What what are the use-cases? Should you even change it? I dive in.
An often cited SEO gripe with Shopify as a platform, is the lack of the ability to edit robots.txt. Something so straightforward with nearly every other CMS and ecom platform, has been so heavily locked-down in Shopify, until now.
Recently (see changelog) Shopify updated their theme system to allow store owners to edit the robots.txt file directly.
User-agent: everyone Allow: / Starting today, you have complete control over how search engine bots see your store. #shopifyseohttps://t.co/Hz9Ijj5h1y
Feature announcement Tweet from Shopify CEO in June 2021
If you are new to robots.txt, I’d highly recommend you heed the warnings on this page and Shopify documentation. In all likelihood – you don’t need to edit your robots.txt at all.
What is a robots.txt, and what does it do?
robots.txt is used by websites (or website owners) to set a series of crawl allowed and not allowed rules for bots to follow. What I mean by bots.
^ for this example, these rules can be written out to mean something like this:
To Googlebot: Please don’t crawl the checkout pages
To All Bots: Please go ahead and crawl everything else
The sitemap: (list of all pages) is over here
Note: You can request and view a /robots.txt URL easily in a web browser, it will load like a normal page full of plain text. While we may think of robots.txt as a file, technically it is delivered as an HTTP response (not a file), same as any other web-page. It just has a Content-Type: text/plain header instead of text/html
nike.com has a very on brand robots.txt file with a commented out first line (#)
It’s important to be upfront and make the clarification that robots.txt is not intended or designed as a way to remove a page from search results. Even though you may have set Disallow, it is still possible for that URL to be indexed, remain indexed, and show up in search results. If you want to prevent a page from getting into the search index or remove it from the index, then you’re better to use a noindex tag, not a robots.txt Disallow. Crawling and indexing are two different things.
A bit about “bots”
You can think of a “bot”, “spider” or “crawler” as roughly the same thing in this context. Anytime a computer program or script programmatically accesses your website – that’s a bot. There are good bots and bad bots: good bots follow your rules, bad bots ignore your rules.
Most of the well-known bots like Googlebot, BingBot, Baiduspider, YandexBot, facebookexternalhit are “good bots”. Good meaning that typically they will read the contents of /robots.txt before making any page access requests to crawl your website, or a specific page on your site. Then they will (usually) follow your rules and not access parts of your site that you have “asked” them not to.
Bad or malicious bots are an entirely different topic, and preventing them from accessing your site, stealing your content or throwing off your web-analytics data goes beyond what you can achieve with a robots.txt file. This is because real “bad bots” will just ignore that the robots.txt file – it doesn’t block them, it’s just a request.
You can do this easily in Shopify Admin > Online Store > Themes > Edit Theme. Open robots.txt.liquid and edit it. If the file doesn’t exist, you can create one by using “default” Shopify robots.txt.liquid content from here.
Shopify will process the file through the standard theme templating engine (so Liquid tags and logic can run) and output under the standard /robots.txt URL route. This means if you’re feeling super advanced, you can even use custom liquid logic in your robots.txt.liquid file!
WARNING: Don’t break your SEO!
If you make a typo, or are following bad advice, robots.txt could easily stop search engines from crawling your site which over time, will be catastrophic to organic visibility and sales from organic search.If you are not sure, about exactly what you are changing, why you’re changing it and know about other options, then don’t change anything.
Even seasoned professionals can introduce bad robots.txt logic which can have wide-reaching effects. Tools like ScreamingFrog can let you test crawl an entire site after changing, to explore and evaluate the effect the effect of robots.txt rules, but require a bit of hands-on SEO experience to use effectively.
If you’re still hell-bent on changing the robots.txt file, I’d highly recommend that you try to understand what you are changing, why you are changing it and to what end before making non-standard customisations. Then after changing it, test and validate the “crawlability” of pages. Then even if you’re sure it’s right – monitor crawl data, coverage and other edge-case issues in GSC and crawl monitoring tools like ContentKing to watch for unexpected changes or side-effects.
If you just want to prevent a page from showing up in Google, Bing or another search engine, then a noindex tag, is usually a better way of doing this. In Shopify, my recommended approach is usually to use the seo.hidden metafield to control noindex tag insertion.
Also the official position of Shopify appears to be that they don’t support edits to this file. I take that to imply that if things do go badly, all they will help you with is restoring it to the default. I wouldn’t rely on Shopify tech support for spoon-fed tech support for robots.txt customisations. So if you go down this path, you will be on your own or you may well need to find a dev or an SEO person to help if things don’t quite go right.
Official Shopify robots.txt info:
Highly recommend that you refer to the official Shopify documentation for this, and read their warnings.
Here’s the default / standard Shopify robots.txt.liquid content:
{% for group in robots.default_groups %}
{{- group.user_agent }}
{%- for rule in group.rules -%}
{{ rule }}
{%- endfor -%}
{%- if group.user_agent.value == '*' -%}
{{ 'Disallow: /*?q=*' }}
{%- endif -%}
{%- if group.sitemap != blank -%}
{{ group.sitemap }}
{%- endif -%}
{% endfor %}
Note: Even before this June 2021 update, there have workarounds to edit the robots.txt file on Shopify. Previously if you really needed to change it, then it could have be achieved with EdgeSEO techniques like a CloudFlare O2O proxy + Cloudflare Worker to replace the /robots.txt response on the fly at the network edge with your own robots.txt content. This hacky workaround is no longer needed 🙂
Making changes to the standard robots.txt.liquid file
It’s really as simple as opening the robots.txt.liquid file in the theme and editing it. To be more specific, you could add static customizations above or below the existing content. Or if you understand Liquid, you could modify this. How best to edit the file in a specific situation, really depends on context and is case-by-case.
When should you change robots.txt in Shopify?
Quite honestly if you have to ask the question, the answer is most likely going to be that you don’t need to change anything. However there are certain edge-case situations where changing the robots.txt.liquid file is exactly what you need.
A few use-cases for changing robots
1. Allow internal search result pages
So I’m referring to internal site search URL’s like this:
outdoorshop.com/search?q=red+umbrellas
The default Shopify robots.txt blocks internal site search result pages with this rule here:
User-agent: *
Disallow: /search
Removing that rule is likely to have no SEO benefit in and of itself, and potentially even carries some risks that it will do more harm than good. Potentially introducing crawl and render budget issues.
But in saying that…
Here’s an example of internal search-result pages showing up in Google for “red umbrellas”
Admittedly, I had to skip past rich results like: PLAs, map-pack, PAA and images to get to the the blue-links, organic is so far down these days!
Here’s how that Amazon organic position 1 looks:
Their search result pages have been heavily customized to act as if they are PLP (Product Listing Pages) in and of their own right. You have likely even landed on pages like this in the past. Amazon makes incredible use of internal-search result pages and is a good example of how these pages can be leveraged.
To make this work in Shopify
First of all making these pages has any kind of SEO benefit, is far more work than a robots.txt change. In this hypothetical, a robots.txt change would really be the last step in a list of other strategic, theme, content and technical adjustments.
This entire approach typically only works on high SKU count stores (we’re talking thousands to tens of thousands of products) where the right breath and depth of category, searched for product names naturally translates into useful (to users & Google) internal search results landing pages.
Ideally, you would not just allow crawls, but also have a way of scaleably linking to the high-value pages via internal pages and sitemaps. Might also be good to create a sitemap_useful_internal_searches.xml of all the valuable pages, and add that to the robots.txt as well. Some of this could potentially be automated through GSC data with some kind of custom service running periodic checks like: “IF /search page gets organic clicks, THEN add it to the priority list if not already”
There are a number of scale problems here, with things like how to prioritize which internal-serp pages are important. As well as having a way to detect, and noindex out -ve sentiment and business sensitive queries.
You’ll likely need to adjust your search.liquid template get the basics right. So I’m talking title tags, meta descriptions and the overall semantic structure of H1s, all need adjustment – at minimum.
Ideally this would be used to create a much larger search surface and to discover new opportunity. However, even if a given internal search result starts performing well in organic, you may want to have a way of reacting to this and porting it over to it’s own PLP collections page. This would allow you to introduce more control, make it more useful to visitors, and create more unique content, like a description, FAQ’s, and below the grid sections.
Link aquisition – often people will share links to search result pages, you should probably find ways to encourage this, monitor new monitor backlinks, and make sure those pages get prioritised and indexed in Google.
So this approach is not going to be suitable for 99.9% of Shopify sites out there. It requires quite a bit of upfront planning, strategy, SEO capability and technical implementation. If you simply allow /search pages to be crawlable without any strategy, you are not likely to see any benefit.
2. Allow multi tag pages
You could make multi tag page URL’s. That contain a ‘+’ symbol, indexable. These pages are disallowed in robots for a reason – because they are typically thin duplicate content. You may have a reason and a way to make the content not thin by creatively editing the appropriate collections template/s, and then want to have the pages crawled and indexed.
3. Disallow duplicate collections page URLs being crawled
I saw this mentioned elsewhere, so I’m covering it, but only to try and talk you out of it. I don’t see robots.txt as the correct fix to deal with this problem.
What I’m referring to of course is how Shopify can have multiple URLs of the exact same product. These path variations inevitably get created when a product appears in multiple collections.
Now, you could add a line into your robots.txt file to prevent ALL those path variation URLs matching /collections/*/products/* from being crawled, but you probably shouldn’t.
The reason I say this is, because those pages will still persist in the Google index if internal links pointing at them. My preferred “fix” here is to instead remove the internal links to the dupe collection pages by modifying the collections.liquid file in the right way.
In summary
Shopify has a pretty well thought out robots.txt config out of the box. If you have a good reason to change it, go ahead. But some of the changes I see discussed with robots.txt changes on Shopify raise alarm bells. If it’s not broken, don’t fix it.
If you have any corrections, suggestions, or other use-cases feel free to leave a comment or fire me an email, hi [at] this domain.
Shopping feeds are now part of SEO. Leveraging feed optimisation can lead to better organic and paid search visibility, clicks and performance. This post is my disorganized list of resources and guides that I’ve found useful. Thought it would be worth listing it all out.
Feed optimisation:
My take is that “feed optimization” can mean two distinct things.
Designing and running A/B tests, typically on config or field field + content changes within a feed. Then measuring the impact of variant against baseline. This can be time-based sequential or randomized groupings, or even account based.
Improving the warning/error rate, completeness, accuracy, or feature utilization of a feed, in a more general sense.
Both of these typically will have the same goal, to increase ecom transactions, dollars or ROAS coming from product listings, be they Google Shopping or organic shopping in Google, or another marketplace.
Enabling optimisation, depends on:
Technical capabilities of your CMS
Technical capabilities of your feed app
Internal content management processes
Team skillset and ability to change 1-3
In the case of A/B testing, the feed app is probably the largest “enabler” in terms of giving you flexibility to implement testing hypothesis at scale.
Some feed optimization resources I’ve found useful:
As an SEO guy, Google Ads have always been a closely related but tangential area that I’ve long needed an excuse to learn. There are a couple of nice videos on campaign structure which I’ve found instrumental in learning
It’s difficult to find quality tutorial or learning material above entry level. So if you have any learning resources you’d like to throw into the list, please email me or drop a comment.
I started this list of Regex strings that I find useful in Google Analytics & Google Data Studio. Some examples are specific to Shopify & and some are more generic.
The intended use case for something like RegExp Match filter in GA or in GDS; custom metric formulas.
RegExp match Shopify product URL’s under collections only
Screenshot from Google Analytics showing only Shopify product page paths in collection
In the example above, I wanted to see if a change I made to Shopify theme (to remove these URLs) actually dropped pageviews and landing page hits to those pages. Why I removed them is a separate discussion 🙂
Strip out URL parameters in Google Data Studio
I often use this as custom metric within GDS. It’s bit of a hack workaround to bring some clarity to dirty GA data that has been tainted with dirty URL parameters. If you want to see a clean list of top landing pages ignoring appended URL params, this helps a lot.
For example if you have fbclid’s, custom params, yotpo parameters, recommended product referral parameters etc.
RegExp here:
REGEXP_REPLACE(Landing Page, '\\?.+', '')
Example:
This is a GDS screenshot where I’ve setup a Custom Metric.
Essentially the regex matches part of a string from ? char to anything. So anything question mark and following will be selected, and replaced with ” which is null string, so deleted. So in effect deleting URL parameters. As long as the other metric aggregation is working correctly within GDS they should aggregate okay-ish in GDS, but there are some gotchas, like I with like Ecom Transaction Conversion %’s adding by default which is not correct.
RegExp match home page only
Seems like it should be simple, to filter to home page only but adding a simple text filter contains=’/’ to GA will show you all pages not just the home page. This is not unique to Shopify.
This is useful if you have a lot of messy URL parameters that have yet to be cleaned up. This could be things like eDM referrer URLs, SMS traffic URL’s. Or other custom parameters attached to destination URLs that work their way into GA without having been intentionally filtered out or dropped at point of collection.
Useful if you’re trying to setup a funnel first step in some analytics tracking for example.
(^/collections/([a-zA-Z0-9]|-)*$)|(^/$)
Regexp match the collection list URL in Shopify
For example if you want to see the domain.com/collections page with and without slash, with and without random URL params and but not actual collections pages themselves. Eg:
If you have any other regexp ideas, examples, improvements, tips or tricks you use to better under Shopify data in web-analytics, I’d love you to drop a comment below or send me an email: hi [at] this domain.
I often use something like this for briefing informational/bloggy type article content over to copywriters. It’s to help them get on-point with SEO.
For blog content especially, a frustration I’ve had seems to come from lack of detail in briefs combined with copywriters with a tendency to go in tangents and waffle. I’ve had articles come back with the topic completely changed formatted in comic sans with no sub-heading structure – no joke! So no more basic briefs.
I wrote this template to get some structure going on. Feel free to use.
Side-note: There is an assumption that you’ve already selected a topic and sub-topics based on robust SEO keyword research and content gap analysis, or something like that.
For the sake demonstrating the the below, I’ve chosen a topic at random: “how to clean a makeup brush”. You just need to replace the topic specifics with your own.
—copy below here—
Deliverable summary:
1x blog (word)articles to be published on our website. Informational blog articles.
Please follow these rules
Do these things:
Insert facts/figures/references as appropriate
Source these with a link
Include source name in link eg: “Over 33% of statistics are made up, according to a study by “
Insert partial and/or full keywords, but only when it *makes sense* in context
Break the article into a pattern of sections –
This means a pattern of header>paragraph or header>paragraph>subheader>subheader
Keep close to the suggested topic tree.
Format deliverables as a GDoc or Word Doc with native formatting
Use native header 1 for title, header 2 for sub heading, header 3 for sub-sub headings etc.
Write FAQ answers in People Also Ask style. This means succinct, factual, situational: (numeric, yes/no, dollar value, list). Needs to directly answer the question in first sentence.
Some research and link to authoritative sources like: wikipedia/.gov research
Try to use terms in “quotes” nearly verbatim like in the reccommended article structure.
If you think it is necessary to improve readability, please tweak the sub-topic order and/or wording, but try not to stray too far from what has been suggested
Aim roughly for a word count.
Communicate if you think you need more or less time/words.
Don’t do these things
Focus on our brand or products
Write sales copy (we will insert this ourselves, if necessary)
Over-use keywords
Change the article topic
Change the FAQ questions
Link on article topic terms. If the article is about red lollipops, then don’t link to someone else on the term lollipops, red, lollipop stick, or best lollipops etc.
Force yourself to the word count.
Article details
Item
Description
Publishing website/s (for context)
List of websites
Audience
Audience is typically female 18-65, Kiwis, Australians but also US market. Really anyone who is interested in beauty/cosmetics and looking up stuff online. Keep this in mind, you’re not writing for a science journal, but including some scientific terminology, facts and figures is ok if it is explained.
Word count (roughly)
~1200
Topic
eg: “How To Clean Makeup Brushes”
Things to talk about
eg:
cleaning equipment: white vinegar, lemon, liquid brush cleaner, iso alcohol, castille soap, baby shampoo, warm water, olive oil, dish soap, paper towel
process: please go into a step + paragraph pattern with specific steps
<p> intro paragraphs (2-3) <h2> frequency / health of cleaning makeup brushes <p> few paragraphs <h2> types of brushes <p> intro <h3> type 1 <h3> type 2 etc… <h2> howto a step-by-step guide <h3> 1. xyz <h3> 2. xyz <h3> 3. xyz etc <h2> signs to replace your brush <h2> How to clean beauty blenders & sponges <h3> [step by step same as above] <h2> FAQ’s (IMPORTANT: use PAA style answers to these) <h3> “Can I use shampoo to clean makeup brushes” <h3> “Why clean makeup brushes with olive oil?” <h3> “Should I wash my makeup brushes with hot or cold water?” <h3> “What happens if you don’t clean your makeup brushes?” <h3> “How often should you clean makeup brushes?”
If you’ve spent time editing out wacky copywriter formatting “choices” and word processing-isms then you know the pain here.
The situation:
Brief over a topic skeleton (me, 15 min)
Draft written (them, a week)
Edits suggested (me, 10 min)
Edits made (them, 1-2 days)
Final review (me, 10 mins)
Copy all & paste into CMS (me, 30sec)
Manually clean up formatting in CMS (me, 5-10min)
Clean up formatting made easy
If you don’t publish at high velocity, or have never really experienced this, then that’s understandable.
However, when working with text content at scale like in SEO agencies, or other content agencies. Eliminating 5-10 mins from the production pipeline adds up you’re publishing 20 blog posts at a time.
Some of this can be avoided with very specific initial formatting rules as part of a content brief, but even then there are issues. There is also the problem of different writers having different habits when using document-processors, with double lines, double spaces, formatting changes away from default, font choices, bullet formatting, title formatting etc. Every formatting diff adds up and needs to be normalized for publishing into a CMS.
I usually try to get copywriters to stick to formatting guidelines like these in a word processor.
Default heading formats (heading 1,2,3 etc) –
No font-sizes, or bold or colours changes away from defaults
If list use list formatting, don’t paste in a symbol, or type a number.
If table, leave formatting stock
Don’t add sources down the bottom
Don’t change link colours/styles from stock
But even then I’ve seen some wild stuff coming back.
Publish to your CMS like a Shopify or WordPress blog without formatting & styles
There are always better ways, and different tools this is one way I’ve found which works quite well for me. If you have a different or better way to do something similar, feel free to slide into the comments below.
I made this list purely out of interest because there is some great Technical SEO content out there that is under-rated and I wanted to do more justice than a bookmark 🙂